Diese Prozedur kann relativ homogene Fallgruppen aufgrund ausgewählter Eigenschaften identifizieren, wobei ein Algorithmus . This procedure attempts to identify relatively homogeneous groups of cases based on selected characteristics, using an algorithm . Cluster analysis with SPSS: K-Means Cluster Analysis.
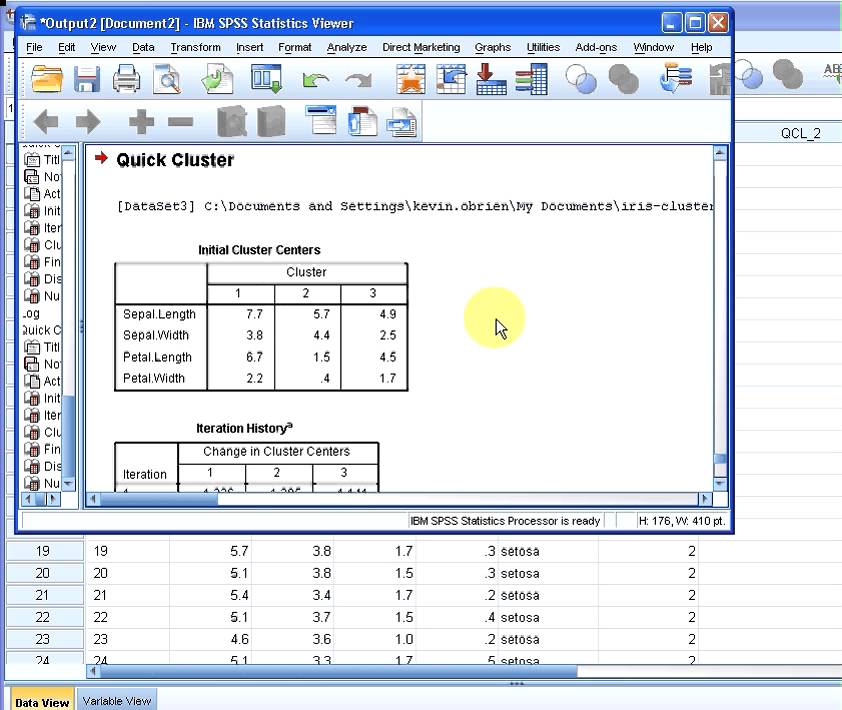
Cluster analysis is a type of data classification carried out by separating the data into groups. Clusteranalyse: Grundlegende Techniken hierarchischer und K-means-Verfahren. Clusteranalyse, wie es von SPSS erstellt wurde. SPSS offers three methods for the cluster analysis: K-Means Cluster, Hierarchical Cluster, and .
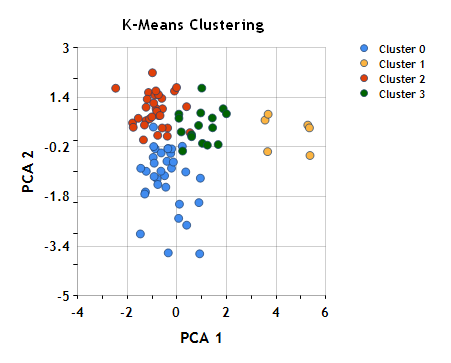
SPSS offers two separate approaches to cluster analysis, K-Means clustering (also called Quick clustering) and Hierarchical (or agglomerative) . Agglomerative (start from n clusters, to get to cluster). Divisive (start from cluster, to get to n cluster). What criteria can I use to state my choice of the number of final clusters I choose. A student asked how to define initial cluster centres in SPSS K-means clustering and it proved surprisingly hard to find a reference to this online .
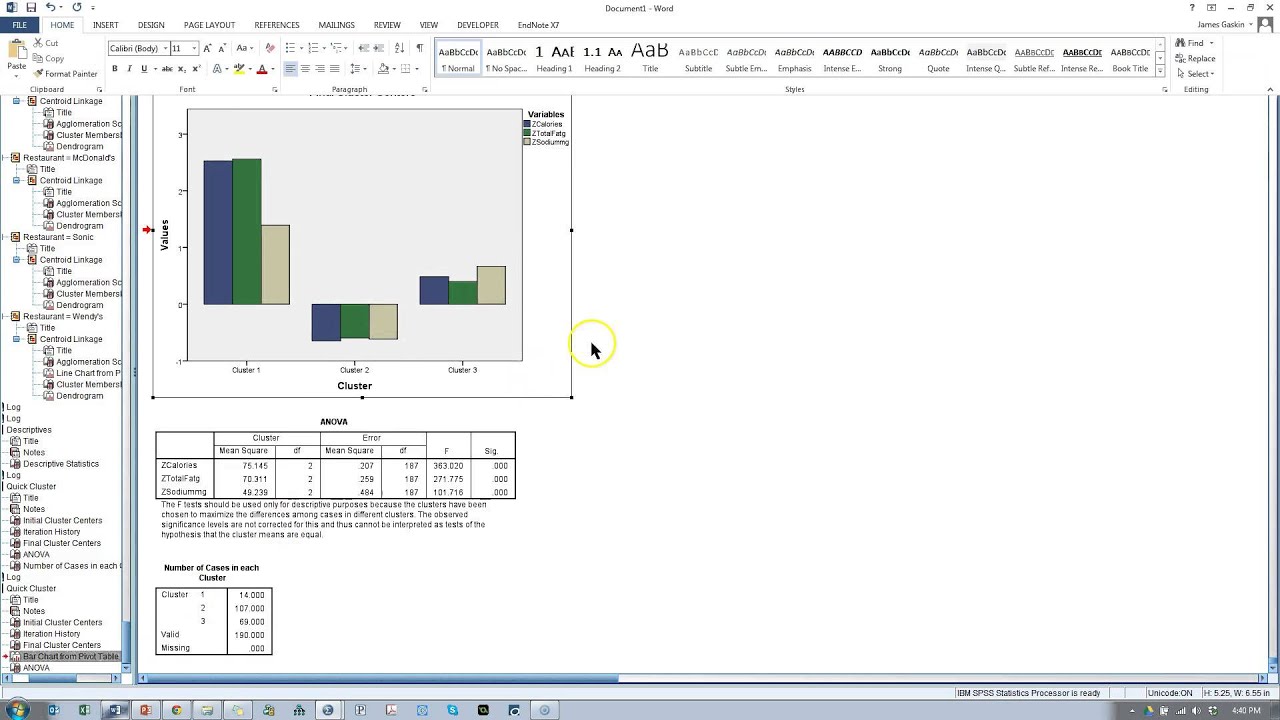
K-means cluster analysis is a tool designed to assign cases to a fixed. The K-Means Cluster Analysis procedure begins with the construction of initial cluster. In k-means clustering, you select the number of clusters you want. SPSS has three different procedures that can be used to cluster data: hierarchical cluster . Social scientists use SPSS (Statistical Package for the Social Sciences) to conduct cluster analyses.
Agglomerative clustering, like K-Means, requires you to specify the number of clusters. In the GUI for FACTOR analysis (Analyze Dimension Reduction Factor), you have. SPSS – Using K-means clustering after factor analysis. K-Means is an optimization problem where basically you want points in the same. Verfahrensmerkmale der Clusterzentrenanalyse (K-Means-Verfahren) ____ 46.
K-Means-Analyse bei bekannten Clusterzentren . SPSS, but an implementation of hierarchical clustering is.